
[Tool] Jupyterhub - Efficiently manage Jupyter notebooks in cloud environments
Jupyter notebooks are the de-facto standard for data analysis and that’s what most data scientist like to use when working on their project. Their simplicity and ease of use made them extremely popular and well accepted by the community.
From the infrastructure/system administration point of view unfortunately the situation is more complex. Jupyter notebooks usually require custom environments and resources, which can make their deployment tedious due to the long and custom list of requirements.
Well… not anymore!
It is possible to deploy a new tool called Jupyterhub that allows easy management of Jupyterlab instances for data scientists. I found this project very interesting and well-integrated with Kubernetes, which was a big plus for its adoption.
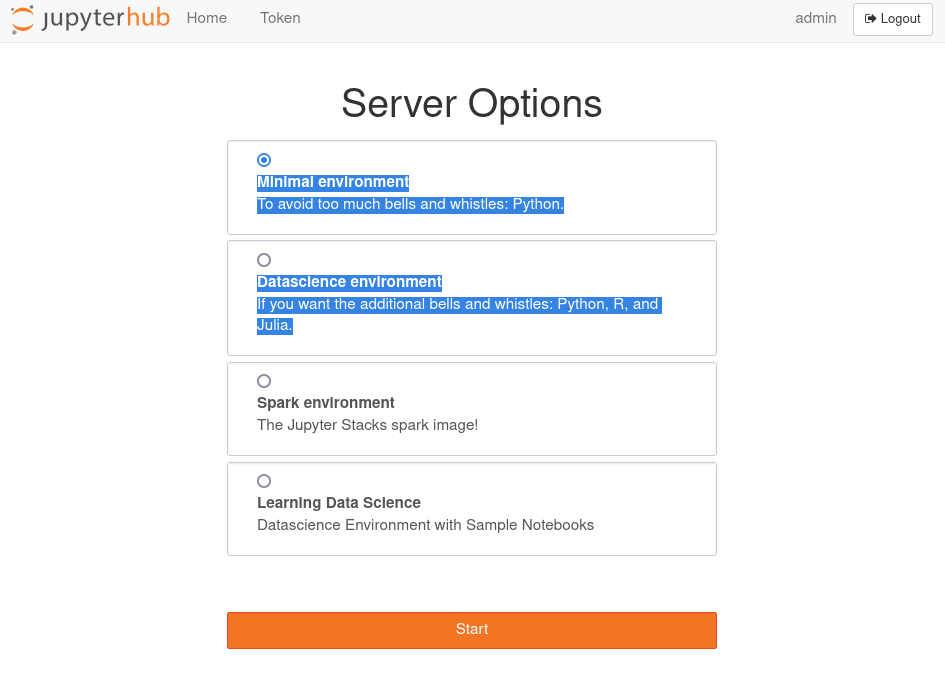
Jupyterhub menu
From the main interface is possible for data scientists to spawn a Jupyterhub instance of their choice and start working right away.
Combine that with containers and a container orchestrator like Kubernetes and what you get is a way to dynamically create environments as you please.
A couple of best practices that I have identified when deploying JupyterHub:
-
Assign every Jupyterlab pod to a dedicated machine - In our experience, sharing machines across data scientists do not work well since they tend to use 100% of the available resources. I have also noticed that setting CPU limits seems to slow down processing even when we are far from reaching the limitation. This is maybe due to the aggressive CPU throttling on certain kernels. We prefer to assign a single Jupyterlab instance per machine and avoid setting CPU limits.
-
Make good use of preemptible instances - Preemptible instances (also called spot instances) are machines that are given you at a fraction of the price but can be reclaimed by your cloud provider at any moment. Make sure to include some profiles using preemptible machines (and let your data scientists know about that!). For certain use cases, the disruption is minimal and they work just fine!
-
Keep an eye on the size of Docker images - As Kubernetes schedules JupyterLab instances on brand-new machines, these machines need to pull the container image before being able to start the pod. Make sure your Docker images are as small as possible. Another alternative to reduce startup time is to have a couple of spare machines with pre-pulled images waiting for a Jupyter Notebook to be scheduled… We found this solution too expensive for a data science team since the instances that they schedule tend to be resource heavy and consequentially quite expensive to run idle.
-
Use node selectors to assign a Pod to a node pool - Node selectors in Kubernetes are probably the easiest way to assign a pod to a machine. I find them easier to use than Pod taints and tolerations, and they fit better this particular use case.
Here you have the list of my recommendations for a Jupyterhub deployment. In the next weeks, I would like to spend some time talking about more advanced use cases and deployments. Lots of interesting things ahead!